
关于本站
1、基于Django+Bootstrap开发
2、主要发表本人的技术原创博客
3、本站于 2015-12-01 开始建站
情景: 最近有个项目是提取CAD的内容到txt文件。txt的默认编码是ANSI,在简体中文的Windows系统中ANSI编码就是GBK编码。但是CAD文档里面有些特殊字符和utf-8编码下才能识别的字符。所以要保存的txt文件得是utf-8编码。那问题来了,Python内置的Open方法没有可以设置编码的...
Python内置的open方法可以读写文件,但是只是ANSI字符编码或者二进制的形式。代码如下:
#coding:utf-8 f = open(r'./1.txt', 'w') f.write(u'中文:你好') f.close()
我用Sublime Text打开可以看到编码格式:
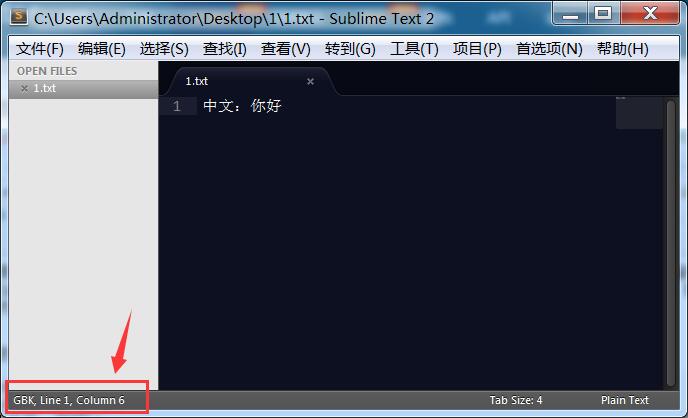
就算我设置coding是utf-8也无济于事。再说这个coding也不是这是这个的。(更多open方法的用法大家可以自行查一下)
这是读写utf-8编码的文件得另寻他路,使用codecs模块。
#coding:utf-8 import codecs f = codecs.open(r'./1.txt', 'w', encoding='utf-8') f.write(u'这才是utf-8编码的文件') f.close()
这次用Sublime Text打开发现确实是utf-8编码了:
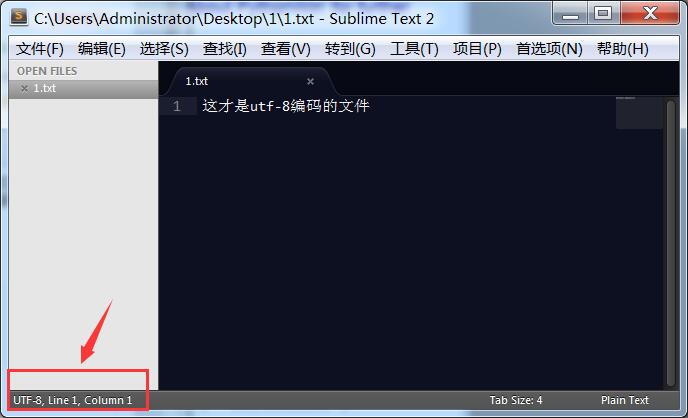
这个codecs的open方法和Python内置的open方法用法很像,多了一个encoding参数可以指定编码格式。
要读写的文件是什么编码就对应写上去即可。codecs写文件时,第2个参数是'w',读文件时,第2个参数是'r'。这些和Python内置的open方法一样。
同样,codecs.open也支持二进制的形式。
另外,两个open方法想输入回车换行的话,可以写入'\r\n' 即可换行。
杨仕航
utf-8这种编码会在一些特殊的文件格式中使用,比较经常用
2016-05-19 09:03 回复