
关于本站
1、基于Django+Bootstrap开发
2、主要发表本人的技术原创博客
3、本站于 2015-12-01 开始建站
Python对XML文档读写常用有几个模块:
1) xml.etree.ElementTree
2) xml.dom.*
3) xml.sax.*
最快要属于etree那个。这3个模块我使用之后,发现还是xml.dom用起来比较顺手。
这个模块是基于XML DOM的,所以各种方法可以参考XML的DOM文档:http://www.w3school.com.cn/xmldom/index.asp
看如下代码,我在代码中注释讲解。
1、写入XML文档
#coding:utf-8
from xml.dom import minidom
#写入xml文档的方法
def create_xml_test(filename):
#新建xml文档对象
xml=minidom.Document()
#创建第一个节点,第一个节点就是根节点了
root=xml.createElement('root')
#写入属性(xmlns:xsi是命名空间,同样还可以写入xsi:schemaLocation指定xsd文件)
root.setAttribute('xmlns:xsi',"http://www.w3.org/2001/XMLSchema-instance")
#创建节点后,还需要添加到文档中才有效
xml.appendChild(root)
#一般根节点是很少写文本内容,那么给根节点再创建一个子节点
text_node=xml.createElement('element')
text_node.setAttribute('id','id1')
root.appendChild(text_node)
#给这个节点加入文本,文本也是一种节点
text=xml.createTextNode('hello world')
text_node.appendChild(text)
#一个节点加了文本之后,还可以继续追加其他东西
tag=xml.createElement('tag')
tag.setAttribute('data','tag data')
text_node.appendChild(tag)
#写好之后,就需要保存文档了
f=open(filename,'w')
f.write(xml.toprettyxml(encoding='utf-8'))
f.close()
if __name__=='__main__':
#在当前目录下,创建1.xml
create_xml_test('1.xml')执行一下这段代码,可以生成xml文档。打开如下:
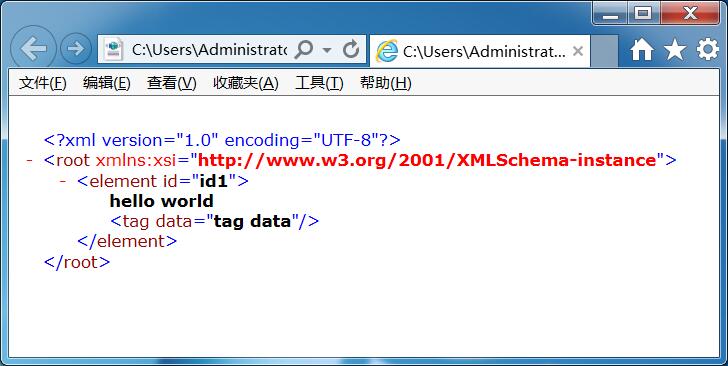
2、读取XML文档
一个节点下,可能存在多个同名的节点。所以,采用下面的XML文档来读取。
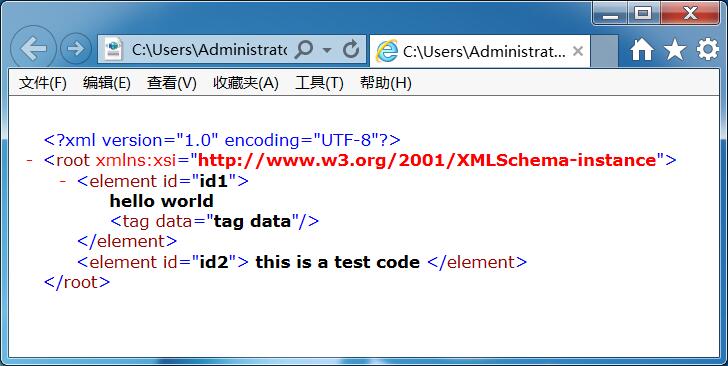
#coding:utf-8
from xml.dom import minidom
#读取xml文档的方法
def read_xml_test(filename):
#打开这个文档,用parse方法解析
xml=minidom.parse(filename)
#获取根节点
root=xml.documentElement
#得到根节点下面所有的element节点
#更多方法可以参考w2school的内容或者用dir(root)获取
elements=root.getElementsByTagName('element')
#遍历处理,elements是一个列表
for element in elements:
#判断是否有id属性
if element.hasAttribute('id'):
#不加上面的判断也可以,若找不到属性,则返回空
print 'id:',element.getAttribute('id')
#遍历element的子节点
for node in element.childNodes:
#通过nodeName判断是否是文本
if node.nodeName=='#text':
#用data属性获取文本内容
text = node.data.replace('\n','')
#这里的文本需要特殊处理一下,会有多余的'\n'
print u'\t文本:',text
else:
#输出节点名
print '\t'+node.nodeName
#输出属性值,这里可以用getAttribute方法获取
#也可以遍历得到,这是一个字典
for attr,attr_val in node.attributes.items():
print '\t\t',attr,':',attr_val
print ''
if __name__ == '__main__':
read_xml_test('1.xml')
raw_input('ok')可以得到这样的结果:
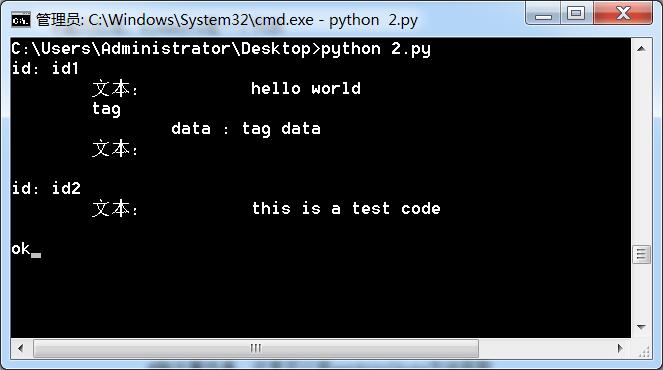
杨仕航
有人问我最近发了好多“Python读写xxx文档”的博文。主要是因为最近项目比较多这种东西 ^_^
2016-04-15 17:08 回复