
关于本站
1、基于Django+Bootstrap开发
2、主要发表本人的技术原创博客
3、本站于 2015-12-01 开始建站
近期研究了一下以图搜图这个炫酷的东西。百度和谷歌都有提供以图搜图的功能,有兴趣可以找一下。当然,不是很深入。深入的话,得运用到深度学习这货。Python深度学习当然不在话下。
这个功能最核心的东西就是怎么让电脑识别图片。
这个问题也是困扰了我,在偶然的机会,看到哈希感知算法。这个分两种,一种是基本的均值哈希感知算法(dHash),一种是余弦变换哈希感知算法(pHash)。dHash是我自己命名的,为了和pHash区分。这里两种方法,我都用Python实现了^_^
哈希感知算法基本原理如下:
1、把图片转成一个可识别的字符串,这个字符串也叫哈希值
2、和其他图片匹配字符串
算法不是耍耍嘴皮子就行了,重点是怎么把图片变成一个可识别的字符串。(鄙视网上那些抄来抄去的文章,连字都一模一样)拿一张图片举例。

首先,把这个图片缩小到8x8大小,并改成灰度模式。这样是为了模糊化处理图片,并减少计算量。
8x8的图片太小了,放大图片给大家看一下。

8x8大小的图片就是有64个像素值。计算这64个像素的平均值,进一步降噪处理。
像素值=[
247, 245, 250, 253, 251, 244, 240, 240,
247, 253, 228, 208, 213, 243, 247, 241,
252, 226, 97, 80, 88, 116, 231, 247,
255, 172, 79, 65, 51, 58, 191, 255,
255, 168, 71, 60, 53, 69, 205, 255,
255, 211, 65, 58, 56, 104, 244, 252,
248, 253, 119, 42, 53, 181, 252, 243,
244, 240, 218, 175, 185, 230, 242, 244]
平均值=185.359375
得到这个平均值之后,再和每个像素对比。像素值大于平均值的标记成1,小于或等于平均值的标记成0。组成64个数字的字符串(看起来也是一串二进制的)。
降噪结果=[
1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 0, 0, 0, 0, 1, 1,
1, 0, 0, 0, 0, 0, 1, 1,
1, 0, 0, 0, 0, 0, 1, 1,
1, 1, 0, 0, 0, 0, 1, 1,
1, 1, 0, 0, 0, 0, 1, 1,
1, 1, 1, 0, 0, 1, 1, 1]
64位字符串 = '1111111111111111110000111000001110000011110000111100001111100111'
由于64位太长,比较起来也麻烦。每4个字符为1组,由2进制转成16进制。这样就剩下一个长度为16的字符串。这个字符串也就是这个图片可识别的哈希值。
哈希值 = 'ffffc38383c3c3e7'
Python代码如下:
#coding:utf-8
#!usr/bin/python2.7
"""
author:Haddy Yang (杨仕航)
data:2016-04-01(代码是4月1号写的,中间太忙了,现在才发布出来)
description:get image's hash value
environ: python2.7 and python2.6
"""
#yum install python-imaging (安装PIL图像库,python2.6)
#PIL官方提供的Python2.6可以使用,2.7不行。
#Python2.7可以用pillow库
#import Image #python2.6 PIL
from PIL import Image #python2.7 pillow
import sys
def get_hash(image_path):
"""get image hash string"""
im = Image.open(image_path)
#antialias 抗锯齿
#convert 转换 L 代表灰度
im = im.resize((8, 8), Image.ANTIALIAS).convert('L')
#avg:像素的平均值
avg=sum(list(im.getdata()))/64.0
#avg和每个像素比较,得到长度64的字符串
str=''.join(map(lambda i: '0' if i<avg else '1', im.getdata()))
#str切割,每4个字符一组,转成16进制字符
return ''.join(map(lambda x:'%x' % int(str[x:x+4],2), range(0,64,4)))
if __name__ == '__main__':
if len(sys.argv)!=2:
print '#sample: python imghash.py filename'
else:
print get_hash(sys.argv[1])看看其他图片的哈希值:

b.jpg :fff3fbe1e181c3ff

c.jpg :ffffdf818080d9f9

d.jpg :ffffcfc7c7c3c7ef
这3张图片的哈希值分别和a.jpg(举例的那张图片)的哈希值对比。对比方法用汉明距离:相同位置上的字符不同的个数。例如a.jpg和b.jpg对比
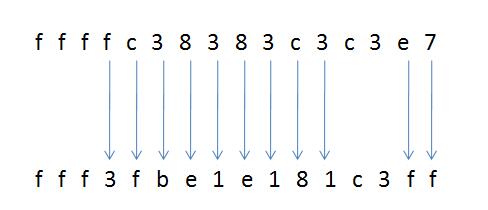
有11个位置的字符不一样,则汉明距离是11。汉明距离越小就说明图片越相识。超过10就说明图片很不一样。
a.jpg和c.jpg的汉明距离是8;
a.jpg和d.jpg的汉明距离是7。
说明在这3张图片中,d.jpg和a.jpg最相似。
大致算法就是这样,汉明距离的代码我没给出,这个比较简单。一般都是在数据库里面进行计算,得到比较小的那些图片感知哈希值。
当然,实际应用中很少用这种算法,因为这种算法比较敏感。同一张图片旋转一定角度或者变形一下,那个哈希值差别就很大。不过,它的计算速度是最快的,通常可以用于查找缩略图。
下篇博文讲一下,余弦哈希感知算法的Python实现。这种算法在实际运用中会比较多。《以图搜图(二):Python实现pHash算法》
startry
这不是dHash吧。。这是avHash
2017-02-14 16:55 回复