
关于本站
1、基于Django+Bootstrap开发
2、主要发表本人的技术原创博客
3、本站于 2015-12-01 开始建站
前几天优化了阅读计数模式,现在就可以拿数据来统计分析。有了明细阅读数据,可以分析出哪些博文相对比较热门、阅读变化等等。我就简单分析一下前7天的数据。
前7天的每天阅读量数据可以统计并展示出来,这个用图表展示比较清晰。对比了一些js的图表插件,决定使用HighChart.js,因为这个图表数据可以用json加载,帮助文档也很完善,使用简单方便。具体帮助可以参考HighChart中文网。先给大家看看图表最终效果图:
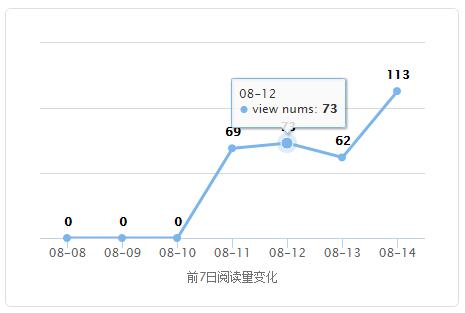
8月11号之前是没有数据的,因为8月11号才上线阅读明细记录的功能(具体细节参考博文《我的网站搭建(第24天) 阅读计数优化》)。把前7天的数据制作成折线图,方便分析趋势变化。
由于HighChart.js使用到的数据是json,所以这里我打算用ajax去获取数据,再加载图表。
为了讲清楚(也为了应付没有看第24天的那篇博文),先交待清楚一些东西。我那个阅读计数应用叫view_record,记录明细的模型是Recorder。具体模型如下:
#coding:utf-8 from django.db import models from django.contrib.contenttypes.models import ContentType from django.contrib.contenttypes.fields import GenericForeignKey from django.contrib.auth.models import User class Recorder(models.Model): """阅读明细记录""" #ContentType关联字段 content_type = models.ForeignKey(ContentType) object_id = models.PositiveIntegerField() content_object = GenericForeignKey( ct_field="content_type", fk_field="object_id" ) #普通字段 ip_address = models.CharField(max_length=15) user = models.ForeignKey(User, blank=True, null=True) view_time = models.DateTimeField(auto_now=True)
下面会用得比较多的是 view_time 日期时间字段,主要围绕它统计分析。
打开该应用的view.py文件,写入如下代码:
#coding:utf-8
from django.http import HttpResponse
from django.contrib.contenttypes.models import ContentType
from view_record.models import Recorder
from blog.models import Blog
import datetime
import json
def get_seven_days_data(request):
"""获取7天内的数据"""
#得到7天的日期
now = datetime.datetime.now() #now还包含小时,分钟等,需要去掉
end_date = datetime.datetime(now.year, now.month, now.day, 0, 0)
start_date = end_date - datetime.timedelta(7)
days = map(lambda x: end_date - datetime.timedelta(x), range(7, 0, -1))
#得到前7天的阅读量
oneday = datetime.timedelta(1)
obj_type = ContentType.objects.get_for_model(Blog)
counts = map(lambda x: Recorder.objects.filter(content_type = obj_type, view_time__range=(x,x + oneday)).count(), days)
#获取HighChart图表设置
chart = {}
#图表设置
chart['chart'] = {"type":"line", #设置为折线图
"borderColor": '#dfdfdf', #设置边框
"borderWidth": 1,
"borderRadius":5,
"margin": 35,
"marginBottom":70
}
#去掉图表标题,太大不好看
chart['title'] = {"text":""}
#X轴设置
chart['xAxis'] = {"categories": map(lambda x: datetime.datetime.strftime(x, '%m-%d'), days),
"tickmarkPlacement": 'on',
"title":{
"enabled":True,
"text":u"前7日阅读量变化"
}}
#Y轴(不写标题,隐藏Y轴)
chart['yAxis'] = {"title":{"text":""}, "labels":{"enabled":False}}
#数据标签
chart['plotOptions'] = {"line":{"dataLabels":{"enabled":True}}, "enableMouseTracking": False}
#数据系列
chart['series'] = [{"name":"view nums","data":counts}]
#图例不显示
chart['legend'] = {"enabled":False}
#右下角版权不显示
chart['credits'] = {"enabled":False, "text":"yshblog.com","href":"http://yshblog.com/"}
return HttpResponse(json.dumps(chart), content_type="application/json")这里的图表相关设置我就不说了,自己看HighChart.js的帮助。此处重点是获取前7天的日期和对应的数据。
日期使用datetime加减得到7天的日期。Recorder筛选需要两个条件,一个是ContentType处理;另一个是日期的范围。这个需要在view_time后面加上__range,并指定范围即可。
再加入url路由设置:
from django.conf.urls import include, url #http://localhost:8000/view_record/ #start with 'view_record/' urlpatterns = [ url(r'^get_seven_days_data$','view_record.views.get_seven_days_data',name='get_seven_days_data'), ]
总路由再添加应用的url路由:
urlpatterns = [
#...其他路径设置就不显示出来了
url(r'^view_record/',include('view_record.urls')),
]接着,修改前端页面显示图表。我把图表放在首页,所以打开对应的首页模版文件index.html(你就根据自己的情况修改),加入如下代码:
{#我所有模版都会基于一个最底层的base.html文件#}
{% extends "base.html" %}
{#此处是head头部分的拓展,加入HighChart.js的引用。我的base.html已经引用了jQuery#}
{% block extra_head %}
<script src="/static/js/highcharts.js"></script>
{% endblock %}
{% block content %}
{#这里还有其他内容我就没显示,此处是body部分#}
{#加入HighChart的容器#}
<div id="container" style="height:300px"></div>
{% endblock %}
{#该block是body部分的底部拓展,通常我是用来写js代码#}
{% block extra_footer %}
<script type="text/javascript">
$.ajax({
type:"GET",
url:"{% url 'get_seven_days_data' %}",
cache:false,
dataType:'text',
success:function(result){
//加载图表
$('#container').highcharts(JSON.parse(result));
},
error:function(XMLHttpRequest, textStatus, errorThrown){
//alert(textStatus);
}
});
</script>
{% endblock %}保存,重启服务,就可以看到前面截图的效果了。
若单单只有这个图表,显得有点空。所以我寻思在这个基础上加一些文字分析说明并显示出来。
这些文字分析说明就一并通过这个ajax获取和显示到前端页面中。json数据结构就需要改动成如下:
{
"chart" : {图表设置},
"texts" : [文字分析数组]
}文字分析说明主要分析了阅读频率、阅读时间段、点击最多的博文等等。代码有点多,我还是一并贴出来。重点和难点是对模型的统计查询。若该部分弄不明白也可以使用SQL语句得到原始的统计查询。
#coding:utf-8
from django.http import HttpResponse
from django.core.urlresolvers import reverse
from django.contrib.contenttypes.models import ContentType
from django.db.models import Count, Max #Django模型统计函数
from view_record.models import Recorder
from blog.models import Blog
import datetime, json
def get_seven_days_data(request):
"""获取7天内的数据"""
#得到7天的日期
now = datetime.datetime.now()
end_date = datetime.datetime(now.year, now.month, now.day, 0, 0)
start_date = end_date - datetime.timedelta(7)
days = map(lambda x: end_date - datetime.timedelta(x), range(7, 0, -1))
#得到前7天的阅读量
oneday = datetime.timedelta(1)
obj_type = ContentType.objects.get_for_model(Blog)
counts = map(lambda x: Recorder.objects.filter(content_type = obj_type, view_time__range=(x,x + oneday)).count(), days)
#7天内的Blog阅读全部明细
seven_data = Recorder.objects.filter(content_type = obj_type, view_time__range=(start_date, end_date))
data = {}
data["chart"] = _get_chart_data(days, counts)
data['texts'] = _get_texts_data(days, counts, seven_data)
return HttpResponse(json.dumps(data), content_type="application/json")
def _get_chart_data(days, counts):
"""get the chart json data"""
chart = {}
#图表设置
chart['chart'] = {"type":"line",
"borderColor": '#dfdfdf',
"borderWidth": 1,
"borderRadius":5,
"margin": 35,
"marginBottom":70
}
#标题
chart['title'] = {"text":""}
#X轴
chart['xAxis'] = {"categories": map(lambda x: datetime.datetime.strftime(x, '%m-%d'), days),
"tickmarkPlacement": 'on',
"title":{
"enabled":True,
"text":u"前7日阅读量变化"
}}
#Y轴(不写标题,隐藏Y轴)
chart['yAxis'] = {"title":{"text":""}, "labels":{"enabled":False}}
#数据标签
chart['plotOptions'] = {"line":{"dataLabels":{"enabled":True}}, "enableMouseTracking": False}
#数据系列
chart['series'] = [{"name":"view nums","data":counts}]
#图例
chart['legend'] = {"enabled":False}
#右下角版权
chart['credits'] = {"enabled":False, "text":"yshblog.com","href":"http://yshblog.com/"}
return chart
def _get_texts_data(days, counts, seven_data):
"""get analysis texts"""
texts = []
#总点击数
__viewed_num(seven_data, texts)
#时间段分析
__anaylsis_hour(seven_data, texts)
#周末和工作日分析
__anaylsis_week(days, counts, texts)
#阅读最多的博文
__max_viewed(seven_data, texts)
return texts
def __viewed_num(seven_data, texts):
viewed_count = seven_data.count()
texts.append(u'前7日总阅读%s次,平均 %.2f次/天' % (viewed_count, viewed_count/7.))
if viewed_count == 0:
texts.append(u'桑心!居然一次都没有,我要好好分析是什么原因 T_T')
elif viewed_count <= 7*2:
texts.append(u'好吧,阅读量有点少,可能宣传不够或者我最近博文写少了')
elif viewed_count <= 7*5:
texts.append(u'目前来说,还需努力,继续写出好的文章')
elif viewed_count <= 7*8:
texts.append(u'^_^ 朋友,若您觉得不错,帮忙宣传一下呗')
else:
texts.append(u'再接再厉,把我的博客弄得更好!')
def __anaylsis_hour(seven_data, texts):
hour_range = [(0,5), (5,8), (8,12), (12,14), (14,18), (18,24)]
hour_viewed_num = map(lambda x: seven_data.filter(view_time__hour__range=x).count(), hour_range)
#获取最大值
max_num = max(hour_viewed_num)
#判断最大值位置
if max_num == 0:
texts.append(u'没有被阅读,无法统计哪个时间段阅读次数最多')
else:
for i, value in enumerate(hour_viewed_num):
if max_num == value:
hour_range_item = hour_range[i]
if hour_range_item == (0,5):
texts.append(u'凌晨0点到5点阅读最多,都是苦比的程序猿吗')
elif hour_range_item == (5,8):
texts.append(u'早上5点到8点阅读最多,我还在睡觉,时区不同吗')
elif hour_range_item == (8,12):
texts.append(u'早上8到12点阅读最多,正常工作时间')
elif hour_range_item == (12,14):
texts.append(u'中午12点到14点阅读最多,不用午休吗')
elif hour_range_item == (14,18):
texts.append(u'下午14点到19点阅读最多,正常工作时间')
elif hour_range_item == (18,24):
texts.append(u'晚上19点到24点阅读最多,要么自学要么加班中')
def __anaylsis_week(days, counts, texts):
week_day_nums = 0
work_day_nums = 0
#获取周末和工作日的阅读量
for i, value in enumerate(days):
if value.isoweekday()>5:
week_day_nums += counts[i]
else:
work_day_nums += counts[i]
texts.append(u'工作日阅读量:%s,周末阅读量:%s' % (work_day_nums, week_day_nums))
#分析阅读量
avg_week = week_day_nums/2.
avg_work = work_day_nums/5.
if avg_work > avg_week:
text = u'工作日平均%.2f次/天,周末平均%.2f次/天。大部分工作中学习' % (avg_work, avg_week)
elif avg_work < avg_week:
text = u'工作日平均%.2f次/天,周末平均%.2f次/天。大部分人挺宅的' % (avg_work, avg_week)
else:
if avg_work == 0:
text = u'什么数据都没有,无法分析工作日和周末情况'
else:
text = u'工作日平均%.2f次/天,周末平均%.2f次/天。难得平均数据一样' % (avg_work, avg_week)
texts.append(text)
def __max_viewed(seven_data, texts):
#对object_id分组计数,并按计数倒序排列。结果是一个数组字典
#获取最多点击次数的博文,这里弄不明白就用SQL语句查询
qs_count = seven_data.values("object_id").annotate(Count('id')).order_by('-id__count')
count_num = qs_count.count()
if count_num>0:
blog_id = qs_count[0]['object_id'] #得到数量最大的id
blog = Blog.objects.get(id = blog_id)
args = [blog_id]
texts.append(u'点击最多:<a href="%s" target=_blank>%s</a>' % (reverse('detailblog', args=args), blog.caption))
if count_num>1:
blog_id = qs_count[1]['object_id'] #得到数量次多的id
blog = Blog.objects.get(id = blog_id)
args = [blog_id]
texts.append(u'点击第二:<a href="%s" target=_blank>%s</a>' % (reverse('detailblog', args=args), blog.caption))代码有点多,大家选择性看看就行。里面有几个地方需要注意的:
1、__anaylsis_hour方法中的filter筛选器使用到条件view_time__hour__range=x,view_time是日期时间字段,__hour是得到该字段值中的小时,__range是范围。组合起来则是得到指定小时范围的记录。
2、__max_viewed方法中的分组计数统计,seven_data.values("object_id").annotate(Count('id')),即得到对object_id字段分组,并对id字段计数。结果是得到一个查询字典,再排序。具体查询统计可以参考一下官方文档。
修改了后台方法之后,还需要对应修改一下前端页面:
{#我所有模版都会基于一个最底层的base.html文件#}
{% extends "base.html" %}
{#此处是head头部分的拓展,加入HighChart.js的引用。我的base.html已经引用了jQuery#}
{% block extra_head %}
<script src="/static/js/highcharts.js"></script>
{% endblock %}
{% block content %}
{#这里还有其他内容我就没显示,此处是body部分#}
<div class="row">
<div class="col-xs-12 col-md-5">
<div class="panel panel-default">
<div class="panel-heading">
<span>前7日阅读分析</span>
</div>
<div class="panel-body" style="height:255px">
{#加一个ul作为容器可被添加文字#}
<ul id="analysis"></ul>
</div>
</div>
</div>
<div class="col-xs-12 col-md-6">
<div id="container" style="height:300px"></div>
</div>
</div>
{% endblock %}
{#该block是body部分的底部拓展,通常我是用来写js代码#}
{% block extra_footer %}
<script type="text/javascript">
$.ajax({
type:"GET",
url:"{% url 'get_seven_days_data' %}",
cache:false,
dataType:'text',
success:function(result){
data = JSON.parse(result);
//加载图表
$('#container').highcharts(data['chart']);
//加载文字
texts = data['texts'];
if(texts.length > 0){
$.each(texts, function(i, item){
$('#analysis').append("<li>" + (i+1) + "、" + item + "</li>");
});
}else{
$('#analysis').append("<li>暂无相关分析</li>");
}
},
error:function(XMLHttpRequest, textStatus, errorThrown){
//alert(textStatus);
}
});
</script>
{% endblock %}这样就可以简单实现图表和文字分析了,效果如下:
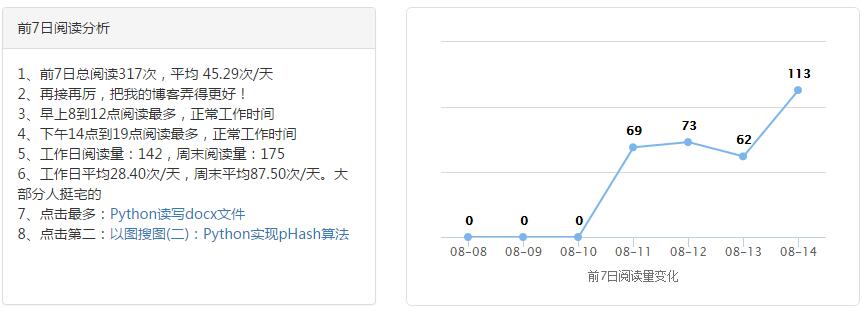
当然,更强大的方法是使用机器学习进一步挖掘数据和分析数据。
dfjk59@126.com
test?
2018-04-17 11:31 回复
dfjk59@126.com
test
2018-04-17 11:31 回复
dfjk59@126.com 回复 dfjk59@126.com
?
2018-04-17 11:32 回复