
关于本站
1、基于Django+Bootstrap开发
2、主要发表本人的技术原创博客
3、本站于 2015-12-01 开始建站
这本《机器学习实战》第1个算法是k-近邻算法,也叫KNN。该算法简单容易理解,十分适合入门。
k-近邻算法是用于分类。分类问题是监督学习算法的一个研究方向。既然是属于监督学习的,就需要1个训练数据集作为判断的基础。
k-近邻算法核心思路如下:
1)建立训练集,该训练集的每个数据已经完成分类。
2)新的数据需要分类的时候,与该训练集每个数据点分别计算距离。
3)取前k个距离最小的点(这个k是我们给定的系数)。
4)判断这些点哪个类别最多,就划分该数据为哪个类别。
参考下图,其中训练集有两个分类。蓝色和红色两种颜色代表两种分类,绿色的点是待分类的数据。
可以明显看出绿色的点和其他点的距离。
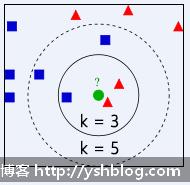
若k=3时,即前3个和绿色点距离最短的点是实线圆部分所示。共有1个蓝色,2个红色。红色居多,说明绿色偏向于红色分类比例大。则绿色的点可以归为红色的类型。
若k=5时,即前3个和绿色点距离最短的点是虚线圆部分所示。共有3个蓝色,2个红色。蓝色居多,说明绿色偏向于蓝色分类比例大。则绿色的点可以归为蓝色的类型。
不要怀疑该算法,这个分类结果和你取的训练集是否具有代表性和k值是否合理有关系。所以,我们用该算法的时候,需要测试训练集和k值是否合理。《机器学习》该书中也举了电影分类的例子,具体可以看该书的第16页。
一般机器学习开发过程中需要如下流程:
1)收集数据:使用各种方法收集数据
2)准备数据:量化数据,就是整理数据为可以计算的数值
3)分析数据:写代码和把数据图形或图表化,观察分析训练集
4)训练算法:k-近邻算法不需要训练,可以直接使用上一步的代码
5)测试算法:计算错误率
6)使用算法
当然,一开始我们使用数据都是比较简单。使用自己拟定的数据,可以直接开始写k-近邻算法的代码。
创建一个knn.py文件。使用如下图的4个点,直接模拟数据:

#coding:utf-8 import numpy as np def create_dataset(): '''模拟创建数据集''' dataset = np.array([ [1, 1], [1.1, 1], [0, 0], [0, 0.1] ]) labels = ['A', 'A', 'B', 'B'] return dataset, labels
此处有4个点,dataset是用numpy创建的二维数组,对应这4个点的坐标。labels对应这4个点的分类名称。
在平面坐标上计算两点之间的距离可以使用欧式距离公式,该公式高中数学中的向量课程就有教学。该公式在《机器学习实战》书中也有说明,如下图:

这些计算都可用numpy模块处理。knn.py文件中,添加如下方法:
def classify0(item, dataset, labels, k):
''' k-近邻算法
item:待分类的数据坐标
dataset:训练集
labels:训练集对应的标签
k:k值,取前k个最短距离
'''
#计算对应元素差值(titl方法,把数据拓展和训练集一样大小)
diff = np.tile(item, (dataset.shape[0],1)) - dataset
#平方和,再开方,求距离
sq_diff = diff**2
sum_sq_diff = sq_diff.sum(axis = 1)
distances = sum_sq_diff**0.5
#按大小排名 argsort返回一个由小到大元素所在位置的下标
#例如 a = np.array([3,1,2])
#a.argsort() 得到 [1,2,0]。即最小的在下标为1的位置,第二小在下标为2的位置
sorted_dist = distances.argsort()
#获取前k个点并统计频率
class_count = {}
for i in range(k):
#取i对应的分类标签
label = labels[sorted_dist[i]]
#累计分类标签个数
class_count[label] = class_count.get(label,0) + 1
#返回频率最高的类别和频率(iteritems是python2的方法,python3可以用items方法)
return max(class_count.iteritems(), key = lambda x:x[1])该方法有以下几点需要注意:
1)tile方法。numpy模块的数组大小一致的话,可以直接加减对应运算。本例的训练集是2*4的二维数组,而参数item是一个两个元素的列表。若循环遍历训练集一个一个对应作减法运算效率比较低。
所以需要把item拓展成2*4的二维数组。运算过程如下图:

2)argsort方法。该方法可以快速得到numpy的数值大小位置。
3)字典求最大值。书中使用operator模版求最大值,其实用max的key参数即可。
在cmd或linux终端打开找到该knn.py文件所在的路径,输入python命令,进入python交互。输入如下命令,测试坐标[0.5, 0.5]会被划分为哪个分类:
>>> import knn >>> dataset,labels=knn.create_dataset() >>> knn.classify0([0.5,0.5],dataset,labels,3)

得到坐标[0.5, 0.5]被划分为B且出现的频率为2。

通过上图可以清晰看出该点分类的依据。先简单介绍和使用k-近邻算法,后面再写k-近邻算法更多的运用。
点击查看相关目录。
相关专题: 机器学习实战