
关于本站
1、基于Django+Bootstrap开发
2、主要发表本人的技术原创博客
3、本站于 2015-12-01 开始建站
之前记录博文被阅读的次数是简单记录一下cookie并+1处理了。随着写的博文越来越多,被阅读的次数也越来越多。就萌生了想统计阅读增长率,统计哪些话题和哪篇博文相对比较热门。
但简单+1的做法只能得到总数,不能得到什么时间段谁阅读过哪篇博文。(另外可以根据阅读明细,分析用户的阅读偏好,推荐博文)
So,自然要对阅读计数动刀子,对其进行优化。这个功能我想写得比较通用,造一个轮子。
完成这个功能的开发之后,发现使用了不少相对高级的东西:装饰器、ContentType、自定义标签等等。
先看看我之前写的阅读计数:
def blog_show(request):
#这是打开某篇博文的响应方法
try:
blog=Blog.objects.get(id=id)
#判断是否存在对应cookie,不存在说明没有阅读过
if not request.COOKIES.has_key("blog_%s_readed" % (id)):
blog.read_num+=1
blog.save()
#... 其他代码我就不拿出来了,写重点部分
data={}
data["blog"]=blog
except Blog.DoesNotExist:
raise Http404
response = render_to_response("blog/blog_single.html",data,context_instance=RequestContext(request))
#设置临时cookie,表示打开阅读过了。该cookie有效期知道浏览器关闭
response.set_cookie("blog_%s_readed" % (id),"True")
return response比较简单,只是记录在read_num字段上。我对新的阅读计数功能要写成一个通用的应用,叫阅读计数器。先创建view_record应用:
python manage.py startapp view_record
这个功能开发写出来的代码有点多,一步一步慢慢来,先看看如何创建数据模型。
1、创建数据模型
要统计什么时候谁访问了哪篇博文,那么就需要一个明细表记录和总表记录总数。
当然可以不用总表记录阅读总数,为了提高网站的访问效率,每次得到博文的阅读总数如果是直接获取到表中的数据,要比每次都用明细表的数据求和要快很多。
打开view_record应用的models.py文件:
#coding:utf-8 from django.db import models #引用ContentType相关模块 from django.contrib.contenttypes.models import ContentType from django.contrib.contenttypes.fields import GenericForeignKey #引用系统自带的用户模型 from django.contrib.auth.models import User class Recorder(models.Model): """阅读明细记录""" #ContentType设置 content_type = models.ForeignKey(ContentType) object_id = models.PositiveIntegerField() content_object = GenericForeignKey( ct_field="content_type", fk_field="object_id" ) #普通字段 #记录IP地址 ip_address = models.CharField(max_length=15) #记录User,这里可能没有登录用户,所以要允许为空 user = models.ForeignKey(User, blank=True, null=True) #阅读的时间 view_time = models.DateTimeField(auto_now=True) class ViewNum(models.Model): """阅读数量记录""" #ContentType设置 content_type = models.ForeignKey(ContentType) object_id = models.PositiveIntegerField() content_object = GenericForeignKey( ct_field="content_type", fk_field="object_id" ) #普通字段,阅读总数量 view_num = models.IntegerField(default=0) def __unicode__(self): return u'<%s:%s> %s' % (self.content_type, self.object_id, self.view_num)
这里用到了ContentType,之前博文《Django点赞功能实现》里面也有使用这个。这个简单来说是可以适应所有对象模型的东西,可以用它代替其他对象。参考:Django中的ContentType文章,不过该文应该是使用旧版本,部分import无效。
2、加入应用
顺手把它加到后台管理中,打开该应用的admin.py:
from django.contrib import admin
from view_record.models import Recorder, ViewNum
# Register your models here.
class RecorderAdmin(admin.ModelAdmin):
"""view recorder admin"""
list_display=('content_type','object_id','ip_address','user','view_time')
ordering=('-view_time',)
class ViewNumAdmin(admin.ModelAdmin):
"""view num admin"""
list_display=('content_type','object_id','view_num')
admin.site.register(Recorder, RecorderAdmin)
admin.site.register(ViewNum, ViewNumAdmin)同时也打开settings.py文件,加入该应用:
INSTALLED_APPS = ( #... 其他应用, 'view_record', )
记得同步一下数据库,本来这些都是细枝末节(自己应该懂的,注意的事情)。为了避免出现低级错误,还是提一下。
python manage.py makemigrations python manage.py migrate
3、阅读计数处理
造了一个轮子为了适用现在的代码,也为了尽可能减少对现在的代码改动。想了许久,决定用装饰器的方法实现计数。
在view_record应用创建一个decorator.py文件,用于放置装饰器方法:
#coding:utf-8
from django.http import Http404
from django.contrib.contenttypes.models import ContentType
from view_record.models import Recorder, ViewNum
#阅读计数装饰器,需要指定模型类
def record_view(model_type):
def __record_view(func):
def warpper(request, id):
try:
obj = model_type.objects.get(id = id)
except model_type.DoesNotExist:
raise Http404
#获取模型的名称做为Cookie的键名
model_name = str(model_type).split("'")[1]
cookie_name = "%s_%s_readed" % (model_name.split('.')[-1], id)
#判断Cookie是否存在
if not request.COOKIES.has_key(cookie_name):
#添加明细记录
recorder = Recorder(content_object = obj)
recorder.ip_address = request.META.get("HTTP_X_FORWARDED_FOR", request.META.get("REMOTE_ADDR", None))
recorder.user = request.user if request.user.is_authenticated() else None
recorder.save()
#总记录+1
obj_type = ContentType.objects.get_for_model(obj)
viewers = ViewNum.objects.filter(content_type = obj_type, object_id = obj.id)
if viewers.count() > 0:
viewer = viewers[0]
else:
viewer = ViewNum(content_type = obj_type, object_id = obj.id)
viewer.view_num += 1
viewer.save()
#执行原来的方法(响应页面)
response = func(request, id)
#添加临时cookie,关闭浏览器之后就过期
response.set_cookie(cookie_name, "True")
return response #返回内容给前端
return warpper
return __record_view若你对装饰器不太了解的话,可以看看我之前写的《我对Python装饰器的理解》。
该装饰器是带一个参数,需要转递模型类进来。例如我的博客模型为Blog,响应打开某个博文的方法是blog_show。如下使用方法:
from blog.models import Blog from view_record.decorator import record_view @record_view(Blog) def blog_show(request, id): #...原来的响应处理方法 pass
给装饰器传递博文的模型类,就可以实现对博文阅读计数。
这里有2个地方需要说明一下:
1)判断是否阅读过了是使用cookie判断,你也可以根据实际情况修改一下;
2)装饰器要求一定有两个参数,request和模型的id。这样才能对具体某个对象阅读计数。
4、后台管理调整
注意,该部分非必须,作为拓展知识讲解。
使用这个阅读计数器,就意味这需要把原先简单计数字段去掉(先别去掉,数据还没迁移过去)。
不过,去掉之后,在后台查看全部博文对应的阅读次数就不方便了。可以这么处理,打开blog应用的models.py文件:
from django.db import models #加入这两个引用 from django.contrib.contenttypes.fields import GenericRelation from view_record.models import ViewNum #博文模型 class Blog(models.Model): """Blog""" #为了方便阅读,我只拿出关键的字段 #旧阅读计数字段(先保留不要删掉,还需要迁移数据) read_num=models.IntegerField(default=0) #关联ViewNum模型,用于显示相关数据 view_num = GenericRelation(ViewNum)
再打开blog应用的admin.py文件:
#coding:utf-8
from django.contrib import admin
from blog.models import Blog
class BlogAdmin(admin.ModelAdmin):
"""blog admin"""
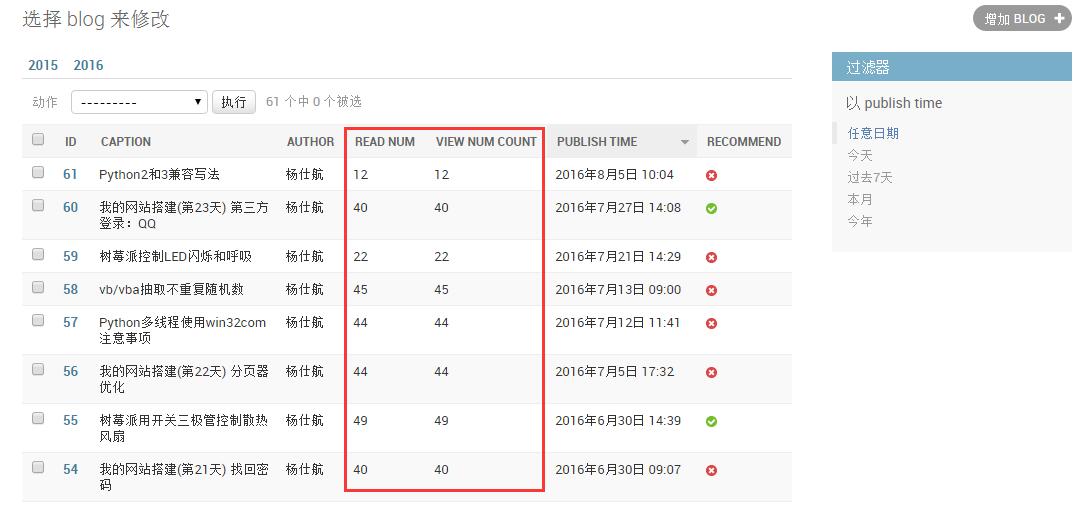
list_display=('id','read_num','view_num_count')
def view_num_count(self, obj):
"""自定义显示字段"""
return sum(map(lambda x: x.view_num,obj.view_num.all()))
admin.site.register(Blog, BlogAdmin)这里也是只放上关键的部分。由于Blog模型新加入的view_num字段是一个模型类,需要自定义字段把数据统计并显示出来。实现这个代码之后,就可以在后台管理中查看对应博文的阅读次数。
注意,此处代码非必须,仅作为知识拓展。
5、迁移数据
注意,若你之前没向我一样简单+1统计数据的话,就不用迁移数据了。
之前的数据在Blog模型的read_num字段上,需要迁移到ViewNum的view_num字段上。这个可以在后台命令行管理中处理,执行 python manage.py shell,打开后台命令行,复制粘贴以下代码:
from django.contrib.contenttypes.models import ContentType from view_record.models import ViewNum from blog.models import Blog def move_date(): for blog in Blog.objects.all(): obj_type = ContentType.objects.get_for_model(blog) viewers = ViewNum.objects.filter(content_type = obj_type, object_id = blog.id) if viewers.count() > 0: viewer = viewers[0] else: viewer = ViewNum(content_type = obj_type, object_id = blog.id) viewer.view_num = blog.read_num viewer.save() move_date() #执行迁移方法
当然这里的代码需要根据你实际情况修改。
迁移完成数据之后,可以打开后台管理界面,看看Blog应用对应的阅读次数是否一致。
6、前端显示
关于前端显示的方法,我也是思考了很久。因为view_record的模型使用了ContentType,每次获取对应的阅读次数有些麻烦,会让代码写得比较多。最后参考django_comments评论库,决定采用自定义标签的方法。
在view_record应用的目录下,创建文件夹templatetags。该文件夹django可以自动识别。
在templatetags文件夹,新建两个文件:__init__.py和view_num.py。打开view_num.py,写入如下代码:
#coding:utf-8
from django import template
from django.contrib.contenttypes.models import ContentType
from view_record.models import ViewNum
#得到自定义标签库,用于注册标签
register = template.Library()
#继承template.Node类,实现render方法
class ViewCountNode(template.Node):
def __init__(self, object_expr, as_varname):
self.object_expr = object_expr
self.as_varname = as_varname
def render(self, context):
#反向解析,从context得到对象
obj = self.object_expr.resolve(context)
obj_type = ContentType.objects.get_for_model(obj)
#获取阅读总数
views = ViewNum.objects.filter(content_type = obj_type, object_id = obj.id)
view_num_all = sum(map(lambda x: x.view_num, views))
#返回阅读总数
context[self.as_varname] = str(view_num_all)
return ''
#注册tag(需要重启服务,才能生效),可以用@register.tag(name=xxx)指定标签名称
@register.tag
def get_view_nums(parser, token):
"""
get object view number
{% get_view_nums for blog as view_num %}
{{view_num}}
"""
tokens = token.split_contents()
#分析参数是否正确
if len(tokens) != 5:
raise template.TemplateSyntaxError("the args must be 5 argument in %r" % tokens[0])
if tokens[1] != 'for':
raise template.TemplateSyntaxError("Second argument in %r tag must be 'for'" % tokens[0])
if tokens[3] != 'as':
raise template.TemplateSyntaxError("Fourth argument in %r must be 'as'" % tokens[0])
return ViewCountNode(parser.compile_filter(tokens[2]), tokens[4])这个自定义标签实现的模式和admin差不多,需要处理的类和注册的方法。一般处理的类是返回结果;注册的方法是判断使用自定义标签的格式是否正确。
这里我简单写了一些注释,鉴于自定义标签的内容也是很多,不方便在这里详细讲解。可以参考Django框架学习的文章。
标签定义好之后,打开对应的前端网页模版。如下方法获取博文对应的阅读次数:
{# 导入阅读器标签 #}
{% load view_nums %}
{% get_view_nums for blog as view_num %}
<p>阅读次数:{{view_num}}</p>使用get_view_nums自定义标签之前,需要导入阅读器标签。其中blog是页面获取到的模型对象,根据自己的实际情况修改。
最后,再把其他和旧阅读计数有关联的地方对应修改。确保没问题之后,才删除旧的阅读计数代码和模型设置。删掉之前的阅读记录字段之后,记得更新数据库。
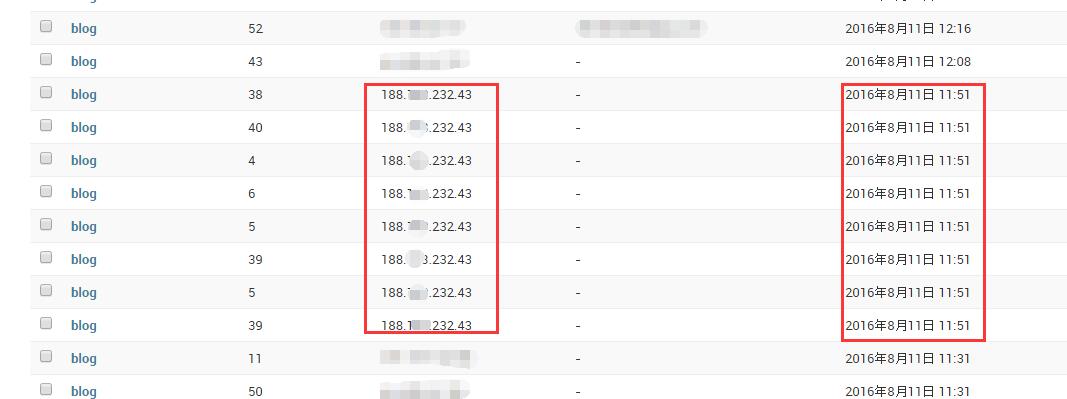
完成这个阅读计数功能之后,就可以查看到哪个人或者哪个IP地址什么时候访问过哪个博文。
我还发现有个相同的IP地址,1分钟内阅读了很多篇博文。目测被其他人爬虫了,也有可能是搜索引擎在爬我的网页。
后面有时间,试一下就弄个统计页面出来。