
关于本站
1、基于Django+Bootstrap开发
2、主要发表本人的技术原创博客
3、本站于 2015-12-01 开始建站
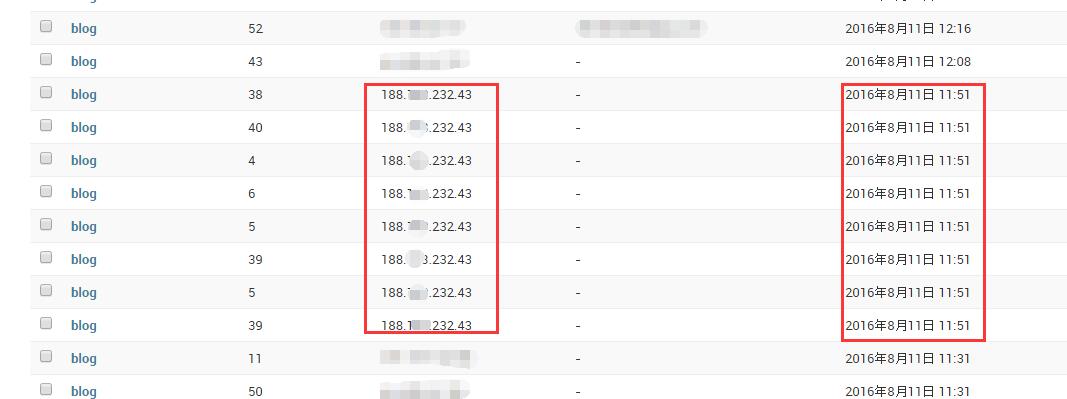
昨天加了阅读明细记录之后,发现访问记录有点奇怪。一个晚上的时间有很多“人”,同样的IP地址在短时间访问了多篇博文。查了一下IP,要么是美国的要么是德国的。种种迹象表明我的网站被爬虫了!
爬虫有利也有弊,爬虫可以让我们的网站容易被其他人搜到。
问题是有些爬虫不遵循爬虫规范,或者是恶意爬取网页、采集数据。也有可能新手为了完成作业写的乱七八糟的代码……
不好的爬虫会耗费大量的服务器资源,影响正常的用户使用。(有些服务器是按流量计费,被爬虫耗费很多流量要交这些额外产生的费用)
头次碰到这种问题,查了不少资料。结合我的网站服务器设置,采用如下方案。
我网站的web服务器软件是apache2.4,在网站的入口进行控制。打开httpd.conf文件。加入如下代码:
<Location /> SetEnvIfNoCase User-Agent ".*(FeedDemon|Indy Library|Alexa Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|Feedly|UniversalFeedParser|ApacheBench|Microsoft URL Control|Swiftbot|ZmEu|oBot|jaunty|Python-urllib|lightDeckReports Bot|YYSpider|DigExt|HttpClient|MJ12bot|heritrix|EasouSpider|Ezooms)" bad_bot #空User-Agaent头 BrowserMatch "^$" bad_bot <RequireAll> Require all granted Require not env bad_bot </RequireAll> </Location>
然后重启apache即可。其他Apache2.2和Nginx设置可以参考张戈的博文:服务器反爬虫攻略。
这里设置是排除指定的User-Agent头和空User-Agaent头。这些爬虫都是比较典型的,收集了一些相关资料整理如下:
AhrefsBot 无用爬虫
ApacheBench cc攻击器
CrawlDaddy sql注入
EasouSpider 无用爬虫
Feedly 内容采集
FlightDeckReports Bot 无用爬虫
HttpClient tcp攻击
Indy Library 扫描
jaunty wordpress爆破扫描器
Java 内容采集
jikeSpider 无用爬虫
Jullo 内容采集
Linguee Bot 无用爬虫
Microsoft URL Control 扫描
MJ12bot 无用爬虫
oBot 无用爬虫
Python-urllib 内容采集
Swiftbot 无用爬虫
UniversalFeedParser 内容采集
WinHttp 采集cc攻击
YandexBot 无用爬虫
YisouSpider 无用爬虫(被UC神马搜索收购了)
YYSpider 无用爬虫
ZmEu phpmyadmin 漏洞扫描
而有些像新手开发的爬虫名字不一定在这个列表里面。这个简单通过判断User-Agaent是否为空排除掉。
若你的服务器是Linux可以用curl命令简单测试一下。
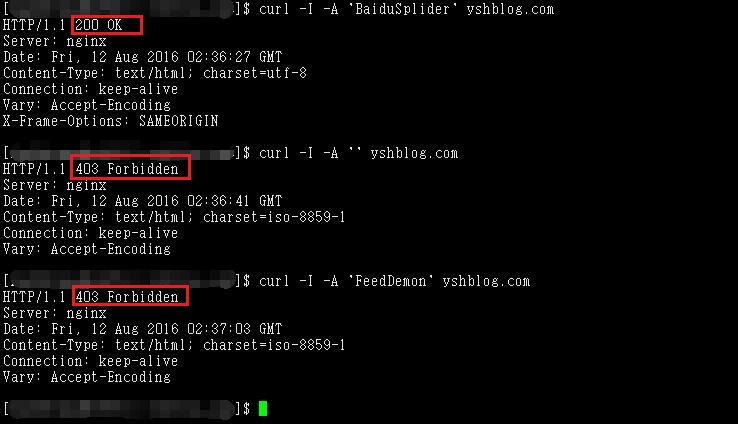
模拟百度蜘蛛得到200允许访问,另外两个都是得到403拒绝访问。终于,我的服务器清静了。